Centos7 PaddleNLP 图片信息提取 基于 SimpleServing 的服务化部署
使用PaddleNLP中UIE模型提取图片信息
环境准备
# 安装PaddleNLP
pip install paddlenlp==2.7.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装PaddleOcr (最新版不兼容 使用2.6版)
pip install paddleocr==2.6.1.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
Server服务启动
# 获取PaddleNLP源码
git clone https://github.com/PaddlePaddle/PaddleNLP.git
cd PaddleNLP/applications/information_extraction/document/deploy/simple_serving/
# 启动服务
paddlenlp server server:app --host 0.0.0.0 --port 8189 --workers 1
–host: 启动服务化的IP地址,通常可以设置成 0.0.0.0
–port:启动服务化的网络端口
–workers: 接收服务化的进程数,默认为1
–log_level:服务化输出日志的级别,默认为 info 级别
–limit_concurrency:服务化能接受的并发数目,默认为None, 没有限制
–timeout_keep_alive:保持服务化连接的时间,默认为15s
–app_dir:服务化本地的路径,默认为服务化启动的位置
–reload: 当 app_dir的服务化相关配置和代码发生变化时,是否重启server,默认为False
开放端口
# 端口添加
firewall-cmd --zone=public --add-port=8189/tcp --permanent
# 重启防火墙
firewall-cmd --reload
# 查看开启的端口
firewall-cmd --zone=public --list-ports
接口请求
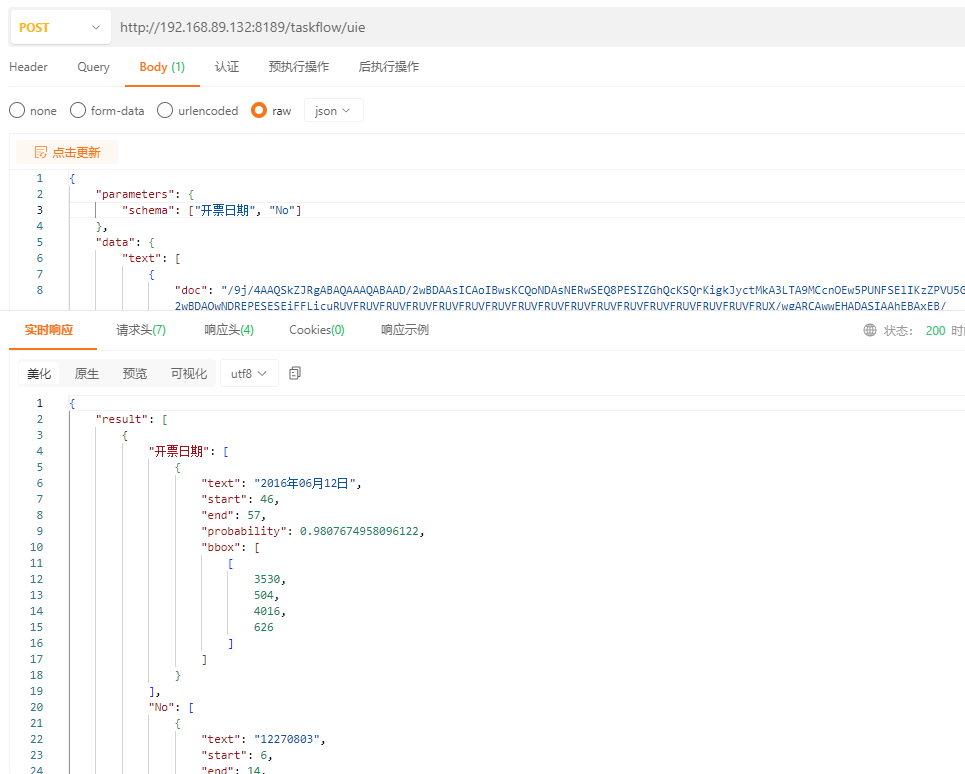
修改使用模型
vi server.python
uie = Taskflow("information_extraction", schema=schema, model="uie-x-base")
| 模型 | 结构 | 语言 |
|---|---|---|
| uie-base (默认) | 12-layers, 768-hidden, 12-heads | 中文 |
| uie-base-en | 12-layers, 768-hidden, 12-heads | 英文 |
| uie-medical-base | 12-layers, 768-hidden, 12-heads | 中文 |
| uie-medium | 6-layers, 768-hidden, 12-heads | 中文 |
| uie-mini | 6-layers, 384-hidden, 12-heads | 中文 |
| uie-micro | 4-layers, 384-hidden, 12-heads | 中文 |
| uie-nano | 4-layers, 312-hidden, 12-heads | 中文 |
| uie-m-large | 24-layers, 1024-hidden, 16-heads | 中、英文 |
| uie-m-base | 12-layers, 768-hidden, 12-heads | 中、英文 |
修改提取字段
vi server.python
schema = ["开票日期", "名称", "纳税人识别号", "开户行及账号", "金额", "价税合计", "No", "税率", "地址、电话", "税额"]
多卡服务化预测
PaddleNLP SimpleServing 支持多卡负载均衡预测,主要在服务化注册的时候,注册两个Taskflow的task即可,下面是示例代码
uie1 = Taskflow('information_extraction', task_path='../../checkpoint/model_best/', schema=schema, device_id=0)
uie2 = Taskflow('information_extraction', task_path='../../checkpoint/model_best/', schema=schema, device_id=1)
service.register_taskflow('uie', [uie1, uie2])